Stop Stuffing the System Prompt
Every memory system injects context into the system prompt. LLMs treat it like wallpaper. There might be a better way.
We were reading a pull request from ByteDance's OpenViking project (their open-source context database for AI agents, 10,000 stars in two months) when we spotted something none of the other ten memory repos we've analyzed do.
Instead of prepending retrieved memories to the system prompt, they inject them as a fake tool call and tool result:
assistant: { toolCall: "search_memories", input: { query: "auth middleware" } }
toolResult: { content: "Team decided to rewrite auth middleware in Q1..." }The model never called that tool. The system fabricated both messages. To the LLM, it looks like it asked for context and received it.
The junk drawer problem
Every memory system I've seen pastes retrieved context into the system prompt. This is fine for a few memories. But the system prompt is the junk drawer of LLM interactions: persona instructions, safety guidelines, tool definitions, output format requirements, few-shot examples, and now your memories too.
Run /context on a fresh Claude Code session:
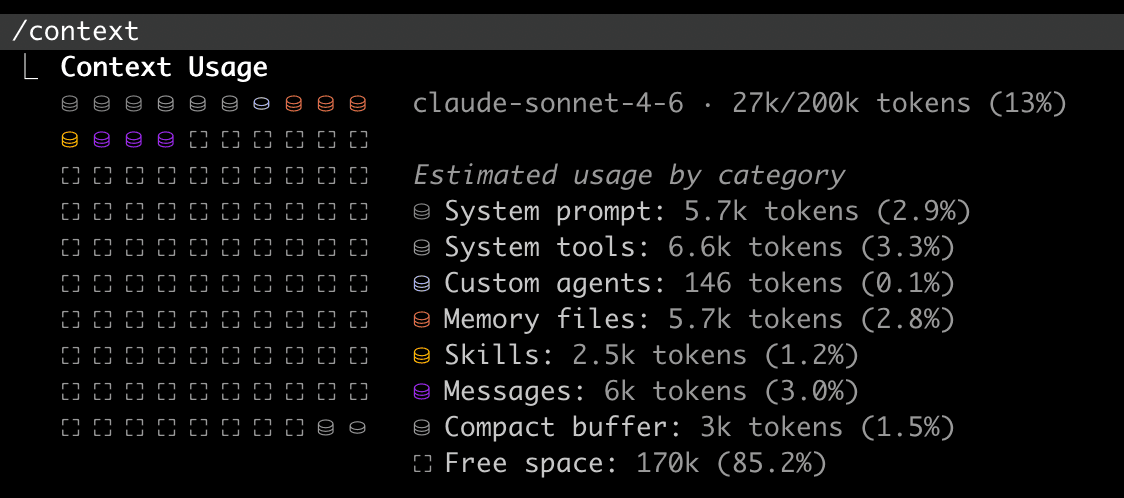
That's a vanilla session with no MCP servers. Add a few and it gets worse:
72% of the context window gone before a single keystroke. Your retrieved memories are going into a room that's already crowded.
The "lost in the middle" phenomenon (Liu et al., TACL 2024) shows LLMs attend most to the beginning and end of their context, with a 20+ percentage point accuracy drop for information in the middle. In the worst case, models with the answer present but in the middle performed worse than models with no documents at all.
The model can still access the information. It just treats it like wallpaper.
Why tool results get attention
Think about how you use a tool. You decide you need information, ask for it, receive it. The result arrives in the conversational flow, at the moment you need it. You pay attention because you asked for it.
LLMs work the same way. Tool results get high attention because training data associates them with task-relevant information the model "requested." A tool result is context for a specific task. A system prompt instruction is ambient background.
By framing retrieved memories as a tool result, the memory gets processed in the high-attention conversational channel instead of the background channel.
Design decisions that matter
The trick itself is two messages. The interesting part is what surrounds it.
Quality-gated thresholds. OpenViking uses 0.15 for per-turn retrieval (wide net, user query disambiguates) but 0.7 for session-start profile injection (high bar, wrong context is worse than none). Proactive injection without a query to anchor relevance needs higher confidence.
Greeting skip. minQueryChars: 4. If the user says "hi," skip retrieval. I've seen production RAG systems that faithfully inject context on every message including "thanks" and "ok."
Graceful degradation. If retrieval fails, don't inject a simulated tool call with empty results. That confuses the model. Fall back to a system prompt note instead.
Two modes. Configurable: simulated_tool_result (default) or text (system prompt fallback). Because not every model or framework handles simulated tool results well.
The four approaches
| Approach | Proactive? | Attention | Cost |
|---|---|---|---|
| System prompt injection | Yes | Low-Medium | Fixed overhead |
| RAG context block | Yes | Medium | Dilutes user query |
| Agent-initiated tool call | No (reactive) | High | On-demand |
| Simulated tool result | Yes | High (theoretical) | 2 msgs per injection |
Key takeaway
Nobody has published an A/B test comparing these delivery mechanisms. The architectural argument for simulated tool results is sound, but "architecturally sound" and "measurably better" are different claims. We're building both modes at Mneme and will publish the results.
The memory field has spent enormous energy on retrieval (hybrid search, graph traversal, salience scoring) and almost no energy on the last mile: how do you get the retrieved context into the model's attention? That last mile might matter more than the retrieval quality itself.
I'm building Mneme at mnem.dev, a memory layer that turns your team's signals into institutional knowledge for AI coding tools. The hard part isn't retrieval. It's the last mile.
Previously: We Cloned 10 Memory Projects and Read the Code · Why Hashing LLM Output Will Always Fail
Related research
The State of Agent Memory in 2026
We audited 10 open-source agent memory projects — 120K+ GitHub stars, $31.5M in funding — to map where the field actually stands. Here's what we found.
Why Hashing LLM Output Will Always Fail
We ran backfill twice. Same signals, same model, temperature=0. Fifteen duplicates appeared. Our content hash caught zero of them.
We Deleted a Feature 4 Days After Shipping It
We built a memory system for AI coding tools, shipped a feature that remembered too much, and deleted it when retrieval quality degraded. Here's what forgetting taught us.
Your AI's Memory Is Someone's Side Project
A 1,500-star MCP memory server vanished overnight when GitHub flagged the maintainer. The AI memory category has a bus-factor problem nobody is talking about.